The Mesh subsystem is used in Fieldpine products to ensure data is available everywhere it is needed
and works regardless of network changes and reliability. The following information is provided
to aid support workers and is not necessarily a 100% accurate description of internal operation.
The mesh layer is primarily responsible for ensuring that data is maintained consistenty across
all machines and databases. Mesh can be configured to read and write SQL databases on different
nodes in the network and these will be maintained to reflect current details. Mesh nodes can include
cloud storage services on NAS devices
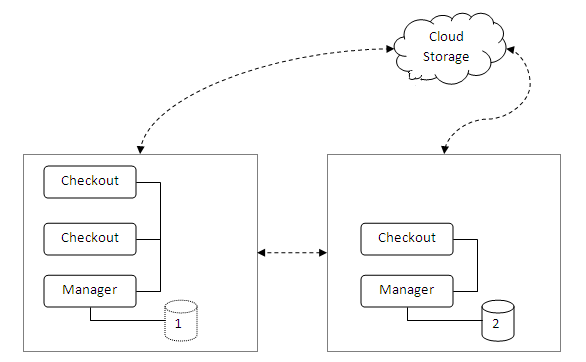
Consider the simple configuration shown.
When a change is made on an checkout or manager pc, the mesh layer:
- Sends to other machines in the store directly via the instore network
- If possible, sends the information directly to the other store.
- If enabled, also sends to cloud storage or NAS devices.
With this method of operation, any component can fail and operation will reasonably continue.
Should all network access to the store fail, you can manually transfer the data on USB devices (or mobile
apps) by simply inserting a USB into store A and then store B. The mesh layer dynamically
decides what data needs to go where
With a mesh system, any authorised node that gets any form of connectivity, can be updated. Naturally there
are a lot of security and control systems as well.
Mesh operation does not require permanent network connections. A laptop operating in head office (connected to network, will
be actively communicating) can be taken on a plane (no network) and edits/changes made to the system. These changes
are buffered until that laptop next connects in some way to the network, and then those changes will
be applied to the other systems
SQL databases are possible at any point (only two are shown for illustration purposes), and
mesh will maintain those databases with current details. Changes made in SQL can be reflected back
to the system and replicated to other databases.
To most users, the mesh layer will be completely transparent; data changed in one place simply
appears in other places automatically
Concepts
For mesh operation, there are a number of concepts to understand. You do not need these
as a normal user, only if you wish to understand how the system works.
RmSystem
The RmSystem defines the overall owner and database in use. The systems in the picture above
would all be part of the same RmSystem. Consider RmSystem to be like "live database" or "test database".
If a machine accidentally receives data for a different RmsSystem,
it is simply ignored.
If you have multiple seperate businesses, each will have a unique RmSystem. If you create
a test database, it will be allocated a RmSystem value.
RmSystem values are designed to be visible, they are like an IP address or domain name. The primarily
identify who this data belongs too. An RmSystem value is four numbers, such as 77,123,89,201192. They are written
with commas between individual numbers.
Key
In order for a machine to be part of an RmSystem (database) it needs a key. This is a very long
random sequence used for encryption control. In order to successfully communicate, a machine
needs the RmSystem and a valid key.
Keys are the minimum security requirement, you can apply more restrictions if you wish
Business Transaction
The actual operation the user is wanting to perform. Such as
- Create or edit a new customer
- Add or edit a sale
- Record arrival of a purchase order
- Record an internal audit, such as operator entry into a secure area
- Request a label print
- Request an email to be sent
Business Transactions are stored in TUBT packets.
There are some variations of Business Transactions, such as Events (TUEV) and Status Packets (TUST),
used for support and monitoring
Physkey
A generated primary key for every mesh record. This key is unique over all systems and uniquely
identifies a single record. Physkeys are very like GUID or UUID values but their internal structure
is slightly more optimised for indexing purposes, they are not simply random numbers. Physkeys are
typically 32 ascii characters, but have excellent compression.
Database-Id
Each database in the network, such as SQL/Server or Access is given a unique "Database-Id". These identifiers
are allocated automatically internally and may change from time to time. They are designed to be unique to
each database instance. In the illustration, databases "1" and "2" would have different database-ids
even though they are part of the same RmSystem.
Database ids are commonly referred to as dbid.
Implementor
Processes Business Transactions and updates strutures and database tables if needed. An implementor
essentially does the work of a transaction. An implementor a piece of code or a program.
Device-id
Each computer also internally generates a unique "device-id" that uniquely identifies this computer. This is generated as
much as possible from something that changes rarely, such as network MAC address. On virtualised servers where even
MAC addresses may not be stable, the system may allocate random UID values and store them in a file for reference.
The intent of this value is to uniquely identify each machine running in the Mesh network. The value of this
number is treated as a unique sequence of characters and different systems (Windows/Android etc) can
use different techniques.
If the device ID changes, extra network traffic is generated. At any single point in time
a whole computer will only have one device-id.
There are a couple of other terms also, but these are much more technical and rarely encountered
Piid
A physical installation id. This is a copy of the device-id at the time the system was first installed. A server capable
of handling multiple databases will have one Piid per database
Instance id
A unique identifier for a single process. Every program that is communicating on Mesh creates a unique
instance id. This can be used to direct communication to a specific single program
Install id
A internal "key" that is generated when a new RmSystem is created. These values are sometimes used when communicating
to external servers as proof that they really are members of an RmSystem they claim to be. Using the install id for this
verification means that the main encryption keys do not need to be placed on internet servers. The Install id can be manually changed if
required, but some disruption to external servers may occur during change over.
Install ids are designed to be protected, but not to the same level is encyption keys
The mesh database is fully able to handle duplicate packet transmission. A node can send exactly the same packet
of data as often as it wishes and receivers are responsible for blocking data they have already processed.
PosGreen
When Mesh is being used on a PosGreen system you may see the following files:
MeshWin.dll
This Dll controls the mesh operation for Windows systems, it is required and may update automatically
TUBT_DATABASE-ID_NNNN_YYYYMMDD.DATI
Main storage log file. These files hold all the transactions generated by the POS, essentially a log of all work deemed important enough to
send to another system. A new file is created each day (times are UTC based, not local time), or if the size exceeds
internal maximums. Ideally, you should retain copies of these files on backup for many years (typically 10 years for tax records)
The index NNNN is a unique number designed to aid replication even if the date is changed unexpectedly. The naming scheme has some
ability to handle
dates being set to the wrong value, when looking at files directly, the date component is what the system claimed the time was, not necessarily the actual calendar date.
After some time (30 to 90 days) these files can be archived and removed, if the system has been on the network and all work is transmitted. You should always retain the
highest NNNN numbered file for each DATABASE-ID
If needed, these files can be manually moved to other machines to transfer transactions
Example File: TUBT_ITB85JUYCJS4IQA_8146_20140813.DATI.
8146 is the NNNN index and ITB85JUYCJS4IQA is the database-id
TUBT_DATABASE-ID_SYSTEM-UID_YYYYMMDD_0.DATI
If the system is enabled for using Fieldpine Online (setting TUBT.SendRm=1) then these files contain
the transactions that are to be delivered to Fieldpine Servers.
These files should be self cleaning, but if you have a large backlog and are certain that replication to Fieldpine
is working, they can be removed.
Global Data Server
When Mesh is being used with Global Data Server you may see the following files:
RetailLogicData_DATABASE-ID_table_0.DATI
Main storage log file. These files hold all the transactions for a given table. They hold all the data
required for a given table.
Details of how mesh transactions are generated and processed by different clients. This information
is background additional knowledge for support staff.
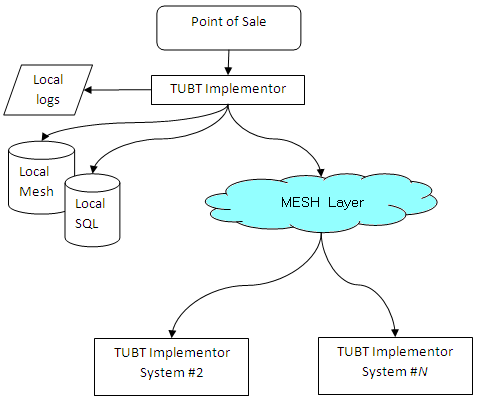
Systems wishing to change data generate Business Transactions and submit
these to an implementor. The implementor understands the individual business transaction and
processes it by validating and storing to local mesh data files and SQL databases. It also sends it to the mesh layer for routing to other nodes in the mesh network.
This sequence of operations has the following effects
- The mesh layer will take care of all packet transmission and routing, queuing data
under network failure conditions.
- Implementors are assigned authorisation levels, and higher level implementors may reverse
or block a local nodes decision. This is rare, but illustrates that nodes do not have the
authorisation to make any change they wish.
- Direct changes to local SQL databases outside the retail system may not be reflected or used. The SQL databases
are primarily output copies of the internal mesh database in use. There are exceptions to this
to cater for circumstances where directly changing SQL databases is required for operational reasons.
- Applications must go through the Implementor for each business transaction. No application
can directly change key structures. The implementor is responsible for transactional integrity.
- Mesh databases are self configuring and do not need columns or tables to be added. This means applications
can access fields or information (via the APIs) that aren't stored in the database. The implementor will
store information into the SQL database when a matching table/column exists.
PosGreen
Transmission:
- System generates a TUBT packet containing a business transaction
- It is stored to local databases and the TUBT_database-id_NNNN* file currently in use
- The individual packet is passed to MeshWin.dll for replication to other sites
- If needed, the packet is written to local mesh data files. Not all packets are kept
locally, only those the Pos determines it needs.
- Packet is sent to Fieldpine Online, if enabled
- If any of the settings TUBT.FileAll TUBT.FileUp TUBT.FileDown TUBT.FileAcross are defined, the
packet is placed in each matching file depending on transaction type. This may mean the packet
is stored several times.
Data packets sent via mesh use a variety of techniques to try achieve maximum application reliability
in the face of constant change from firewalls, virus detection and other external controls.
Packet Construction and Transmission
When a Fieldpine system determines the need to send data to another site it performs the following steps:
- Build an enclosing packet (called TUBT, or TUEV etc)
- Calculates urgency and importance
- Determines for each transmission method if additional encryption is required
- Passes the message to the link level for transmission.
Direct IP
Network identification
» First 4 bytes contains "GNAP"
» If using HTTP/S URL usually contains /GNAP in leading segment
If configured with specific IP addresses, the system will use normal TCP and UDP connections to talk
directly to these systems. On these links, data is optionally encrypted and sent over the socket connection.
Data is always encrypted if crossing from private IP ranges to public IP ranges, or by site setup.
- Direct IP links may use NAT tranversal techniques
- If you are using a VPN over public networks, we leave general traffic encryption to the VPN
Multicast & UDP
Network identification
» Multicast address 239.192.6.x
» Discovery uses 239.192.6.83
On local LAN segments, systems may choose to use multicast to endpoints which terminate automatically at routers.
The multicast addresses are in the local administrative range. The address 239.192.6.83 is used
as a discovery address used to locate other cooperating systems. The discovery protocol allows computers
to find others without needing to be manually configured with IP address.
This address is shared between all Fieldpine systems, but is designed to work across systems that should not be
joined, such as live and test.
Each environment (such as "live" or "test") will choose a multicast address in the 239.192.6.x range as well. This is the
multicast address that environment uses.
Normal UDP packets are also sent to direct host addresses, especially for background work. Logging of
health and status information for example will often use a UDP packet rather than opening a full TCP link.
If you do not enable UDP at your network perimeter, the systems will fall back to TCP or other alternatives.
Internet Mesh
Network identification
» First bytes are header, but no fixed fields (see notes)
» Multiple source and target ports
» Tends to communicate to small number of hosts
» If using HTTP/S URL is typically /GNAP/GNAE
This system involves data routing using internet based hosts. Typically these will be a finite number of fixed hosts
so that data can route between two servers. This method imposes the following mandatory controls:
- If the data contains highly sensitive data, such as passwords, is encrypted with One Time Pad (no key reuse).
- The source packet is fragmented to multiple pieces and potentially joined with other
packet fragments to build a payload
- Each payload is encrypted. Only some encryption techniques are pemitted.
- A header is created containing sender#, message# and urgency indicators.
- Optional variable length Encyption control is added.
- The final packet is sent over the Internet, to either rendevous servers, routing assist servers or
direct to the retailers other stores.
| Messages to send | HELLO | 9.95 |
| Fragmented into pieces | H E L L O | 9 . 9 5 |
| Assembled into payloads | H9L | .EL | 9O5 |
| Encrypted (various techniques) | W3g6FaG | UU7#v | W@h88 |
| Add Headers | From: Store1
Message# 23
W3g6F | From: Store1
Message# 24
UU7#v | From: Store1
Message# 25
W@h88 |
| Add Optional encryption parameters | From: Store1
Message# 23
2646453
W3g6FaG | From: Store1
Message# 24
1185
UU7#v | From: Store1
Message# 25
982746282
W@h88 |
| Transmitted. Ideally using different hosts and possible random time delays |
If a packet is seen by an attacker
- They need the encryption details to decrypt the payload packets.
- They will need all the payloads to reassemble a single message
Email
Where all the retail systems have access to a email account that can be used, data may be transmitted as email with
attachments. Data is chunked to a reasonable size and numbers of emails are generally held low.
These email attachments are encrypted when sent between Fieldpine applications
Manual Means
Data may also be transferred from one site to another via disk storage. This is used as a fallback
when network links are completely unavailable, or also for high volume/low priority information that retailers
do not wish to pay bandwidth charges for.
The most common form of this is USB thumb drives, which the system will automatically read and write when
detected.
Packet Types
Packets are defined using 4 bytes in the header. The list may change without warning and you
should not block by packet type in order to ensure future reliability.
| Packet Type | Meaning | Packet Type | Meaning |
| IDQY | Identification Query.
Who is out there? | IDRP | Identification Response
I am here, I am... |
| TUEV | Transfer Unit, Event
Logging of things that happened | TUBT | Transfer Unit, Business Transaction
Contains business level transactions, eg a sale, product edit |
| GNAP | Generic header.
Not strictly a packet, used to indicate switching protocol | QERQ | Query Exchange Request
Can someone, do something for me? |
| QERP | Query Exchange Reply
Replys to QERQ | QERD | Query Exchange Request Done
Request done or cancelled |
| QERS | Query Exchange Strong Lock
Request to strong lock a request | QERW | Query Exchange Weak Lock
Weakly lock a request |
| TUBS | Transfer Unit Background Setup
Link control and data exchange protocols | TUDA | Transfer Unit, Data
Background syncronization and backup of data |
Filtering Techniques
Customers and ISPs sometimes use filtering techniques for various purposes. The traffic generated
by a retail system is being sent to another part of the retailers environment and should be considered
deliverable.
If you are using Deep Packet Inspection (DPI) or Stateful Packet Inspection (SPI) techniques, then:
- The data transmitted is all application level, between a single customer systems, or sometimes to
vendors, partners or cloud servers. Data is not transmitted to random individuals and there is no mass sharing of
data. This means that most data will be within a single ISP, as retailers tend to use the same ISP at all sites. Cross ISP
traffic is possible and should not be blocked.
- All links use variable length packets containing data.
Typical TCP packet format
Packet Type
4 bytes | Packet length
4 bytes | Payload data
variable length |
Typical UDP packet format
Packet Type
4 bytes | Visible Header
Variable length | Payload data
variable length, encrypted |
- Different transmission methods (direct IP connection, multicast) will include more or less headers on each packet.
- The payload data is encrypted, except where explicitly required not to be, such as the discovery protocol. Sites can alter encryption techniques if they wish. Payload data
may also be fragmented over several network packets.
- The application sends different types of information, some is marked urgent, typically those where a
customer or staff member is actively waiting for a response. Others are background information of lower
priority. Urgent markers are only used in the application for truely urgent data, it is not used as a
priority scheme.
- There is no simple way for external tools to implement Data Loss Prevention (DLP) as payloads are encrypted and exposing the contents
would be a security risk. Packets
are typically only sent to the retailers own systems.